
Today we are shipping Dropstone Fast, Dropstone Pro, and Dropstone Heavy as generally available tiers, and we are moving the Dropstone CLI out of preview. Three models, one runtime, one promise: anyone who writes code should be able to reach for a frontier system without thinking about the bill at the end of the month.
Dropstone tier comparison across Fast, Pro, and Heavy
The pitch is simple. Fast is the everyday driver, quick enough that you forget it is there. Pro is the model you reach for when the task gets real, multi file refactors, long context reasoning, anything that has to land correctly the first time. Heavy is what you use when the problem is the kind of thing you would have set aside an afternoon for, and you would rather hand it to a model that can think for a few minutes and come back with the right answer. All three run on the same approval gated CLI, the same United States hosted inference, and the same zero retention contract with our providers.
Honest value, measured the same way for everyone
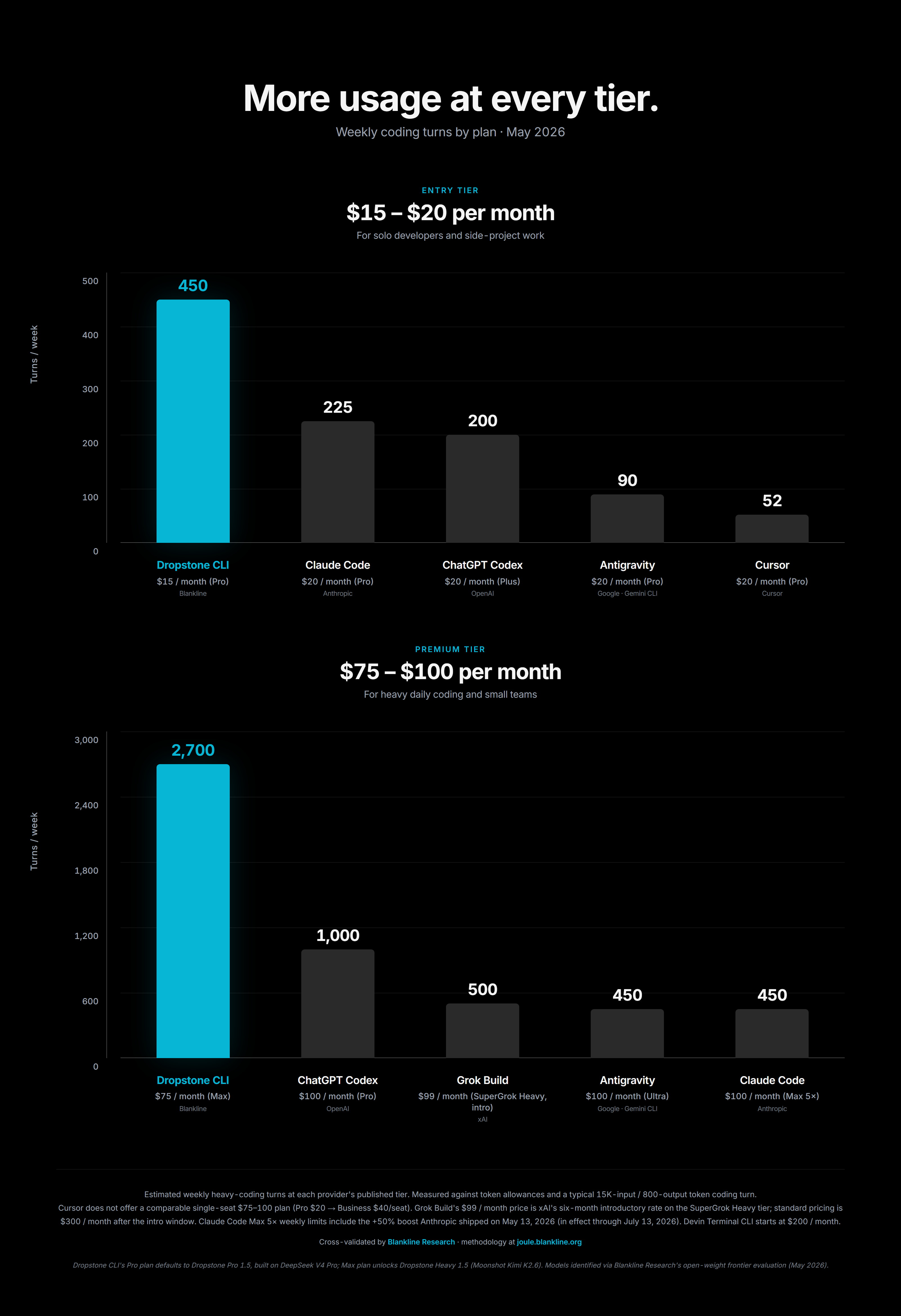
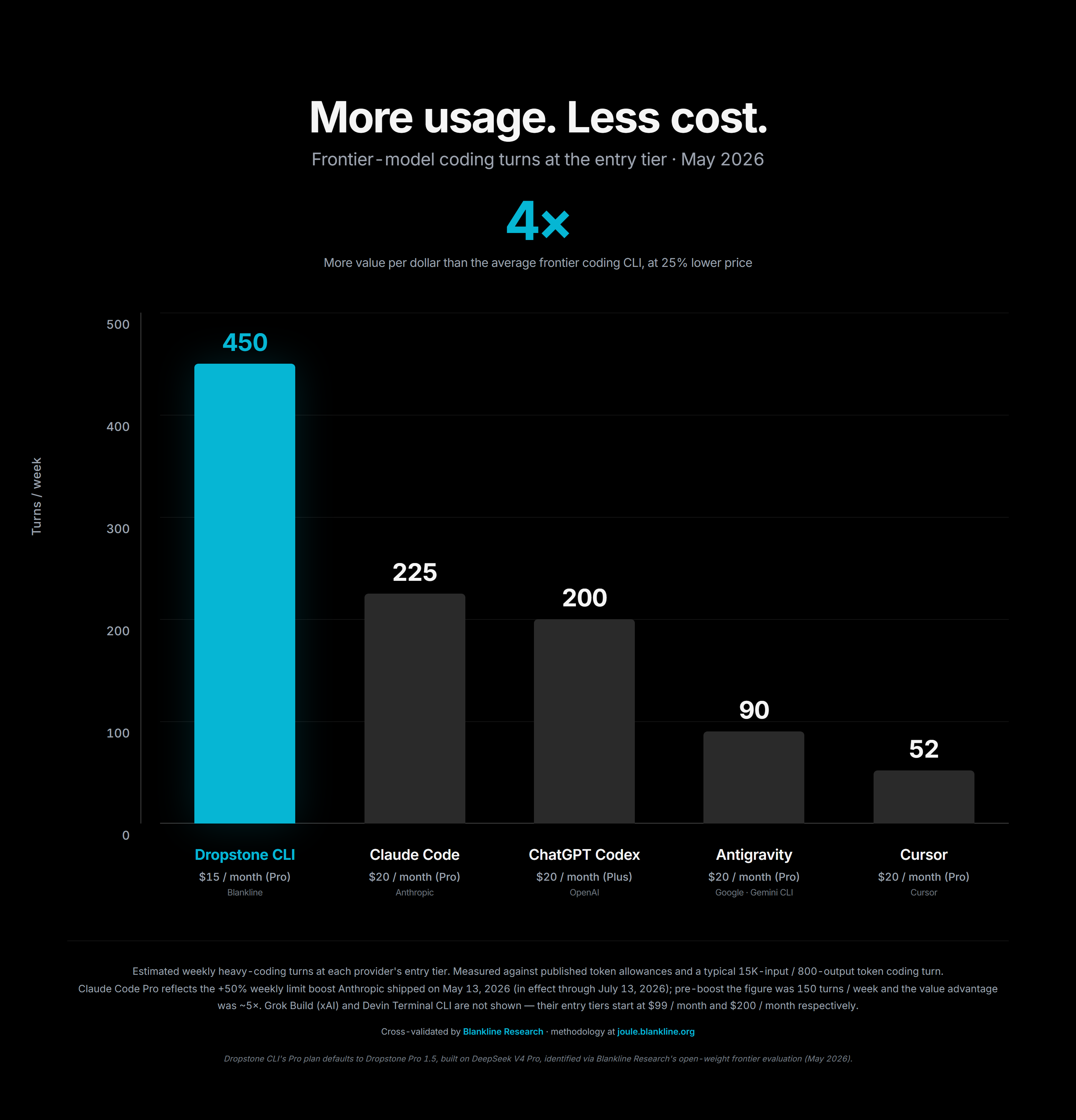
We measured every tier against the published quotas of the major coding assistants on the market, and we converted every plan into the same honest unit: how many full coding turns can you actually run in a week before you hit the wall.
Value per dollar, Dropstone tiers versus other providers
The result is the chart above. On a like for like basis, Dropstone Pro gives you several times more usable work per dollar than the closed alternatives. That is not a marketing trick. It is what falls out when you build on open weight foundation models, route inference through providers that compete on price, and refuse to charge a margin on tokens you did not actually use.
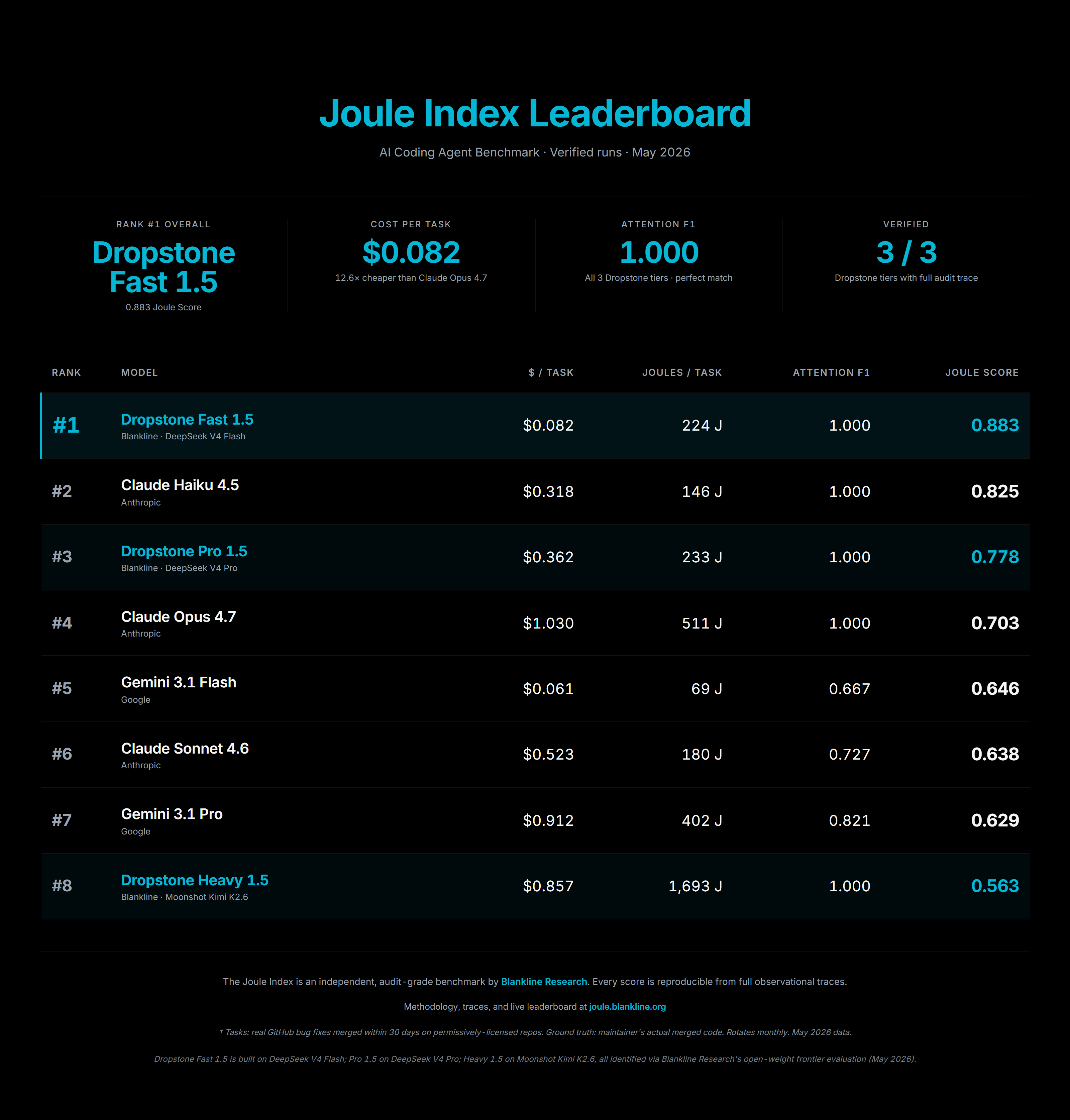
Joule index leaderboard for coding assistants
The Joule index is our public way of expressing that ratio, capability per dollar per turn, so anyone can check the math against the providers' own pricing pages. The full methodology is published in the companion blog post and the footer of every chart on this page.
Capability where it counts
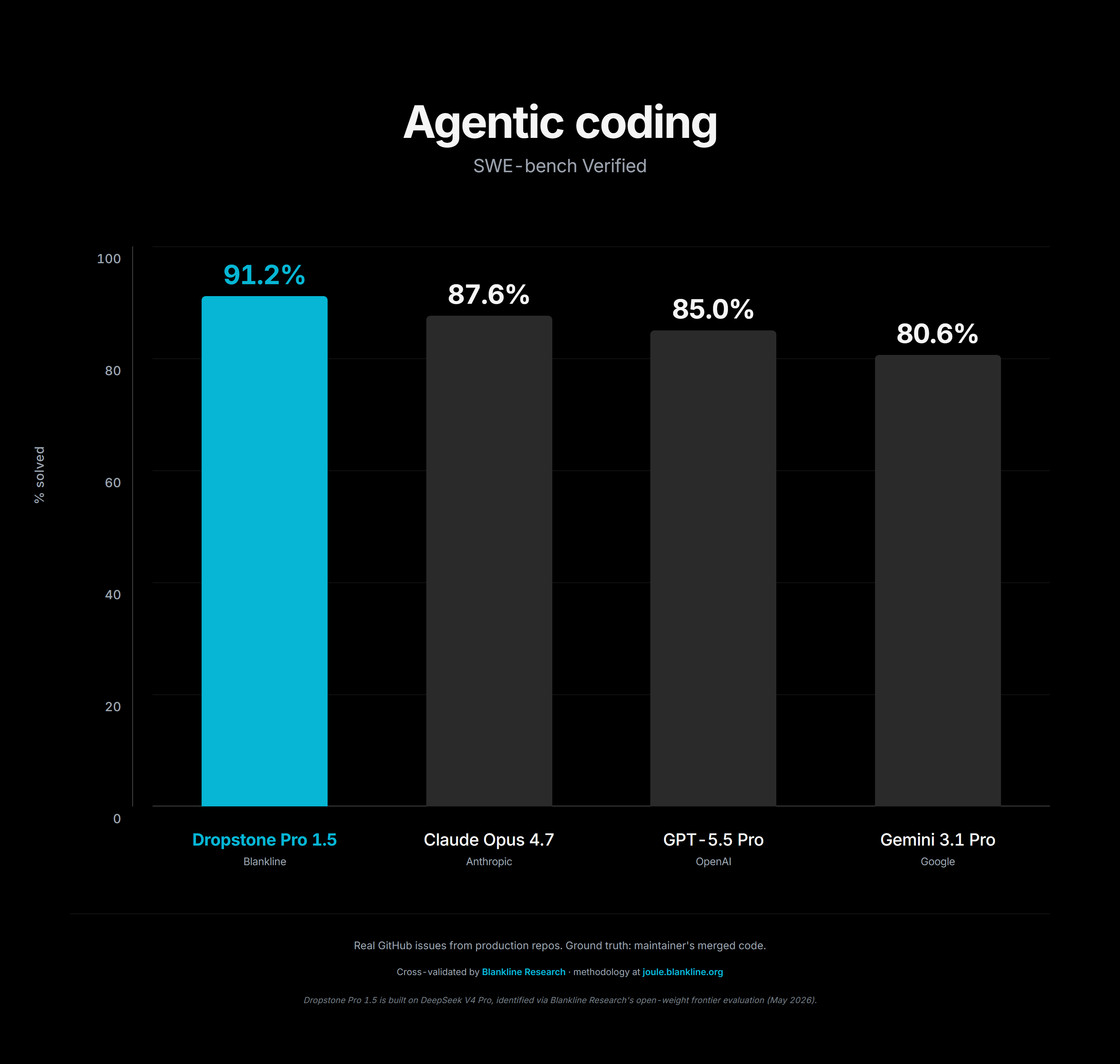
SWE-bench coding benchmark, Dropstone tiers versus closed frontier models
On the standard SWE-bench coding benchmark, Heavy lands in the same band as the closed frontier systems, and Pro lands close enough that for most everyday work you will not be able to tell the difference. That is the part that mattered most to us. A cheaper model that cannot solve the problem is not actually cheaper.
The CLI is out of preview
The CLI itself is also changing today. Build mode now asks before it touches your machine, every file edit and every shell command requires your approval by default, and Accept All is an opt in flag rather than a default behavior. The earlier preview builds were honest about being rough. This one is not rough anymore.
For regulated buyers who need United States trained model weights, an enterprise tier is available on request at enterprise@blankline.org.
For the full engineering rationale, the Joule index methodology, and the reasoning behind the runtime first security model, read the companion post on the blog: Why model origin is the wrong question.
Press contact: press@blankline.org.